所谓搜索引擎,就是通过电脑程序爬行,追踪网页之间的链接。信息经过组织、加工后,向用户提供检索服务,并将检索到的相关信息呈现给用户系统。网友在搜索框中输入关键字显示

1、所谓搜索引擎,就是通过电脑程序爬行,追踪网页之间的链接。信息经过组织、加工后,向用户提供检索服务,并将检索到的相关信息呈现给用户系统。网友在搜索框中输入关键字显示搜索结果信息,就是经过搜索引擎工作后的结果排名。
2.常用搜索引擎( 最下文有福利领取)
目前我们比较常用的搜索引擎有百度搜索引擎,360搜索引擎,谷歌搜索引擎,搜狗搜索引擎,以及各网站站内搜索,比如移动端的微信,各种 APP都有搜索引擎功能。
何谓搜索引擎营销
顾名思义,搜索引擎营销是通过研究网民的搜索行为,将快速、准确的营销信息呈现在搜索结果页面,从而开展营销活动。简单地说,就是利用搜索引擎进行网络营销。
如果用户在搜索引擎中搜索产品关键字,找到你的网站并点击进入,这时你已经通过搜索引擎吸引了一位访问者,如果想通过搜索关键字吸引更多的访问者进入你的网站,就要采取特定的行动,利用搜索引擎吸引更多的访问者,这就是搜索引擎营销。
有两种主要的搜索结果:1、自然搜索结果2、付费搜索结果
一、搜索的自然结果
“自然搜索结果”是指用户在搜索关键字时自然出现的、与关键字最相关的结果,这里我们要了解一下 SEO,它不仅能帮助你的网站出现在关键字搜索结果中,而且还能帮助提高“结果”的排序。
事实上,谈到搜索结果时,多数人都会提到自然搜索结果,60%的访问者都会去点底自然搜索结果,因为这是与其搜索关键词最相关的网页。所以自然搜索结果是搜索引擎营销的一个重要组成部分。尽管这样做花费了很长的时间和精力,但效果持久,可以有效地节省企业预算。
二、付费搜索结果
很多搜索网站通过付费搜索结果获利。搜索结果主要是通过付费产生的,当用户搜索关键字时,他们自己的网页信息就会出现在搜索结果中。这种方法可以迅速吸引访问者,尽管效果很好,但它需要大量的预算来支持。
无论是免费搜索引擎优化(SEO)还是付费搜索引擎竞价(SEM),搜索引擎营销都是网络营销的重要策略,许多企业想方设法将自己的营销信息展示在百度首页上,以获得更多的曝光,从而获得更多的用户。
百度搜索引擎原理
Baiduspider是百度搜索引擎的一个自动程序,它的作用是访问互联网上的网页,建立索引数据库,使用户能在百度搜索引擎中搜索到您网站上的网页。
互联网信息爆发式增长,如何有效地获取并利用这些信息是搜索引擎工作中的首要环节。数据抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、保存、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做“spider”。
spider从一些重要的种子 URL开始,通过页面上的超链接关系,不断的发现新URL并抓取,尽最大可能抓取到更多的有价值网页。对于类似百度这样的大型spider系统,因为每时 每刻都存在网页被修改、删除或出现新的超链接的可能,因此,还要对spider过去抓取过的页面保持更新,维护一个URL库和页面库。
互联网资源庞大的数量级,这就要求抓取系统尽可能的高效利用带宽,在有限的硬件和带宽资源下尽可能多的抓取到有价值的资源。
互联网中存在着大量的搜索引擎暂时无法抓取到的数据,被称为暗网数据。一方面,很多网站的大量数据是存在于网络数据库中,spider难以采用抓取网页的方式获得完整内容;另一方面,由于网络环境、网站本身不符合规范、孤岛等等问题,也会造成搜索引擎无法抓取。目前来说,对于暗网数据的获取主要思路仍然是通过开放平台采用数据提交的方式来解决,例如“百度站长平台”“百度开放平台”等等
spider在抓取过程中往往会遇到所谓抓取黑洞或者面临大量低质量页面的困扰,这就要求抓取系统中同样需要设计一套完善的抓取反作弊系统。例如分析url特征、分析页面大小及内容、分析站点规模对应抓取规模等等。

通过熊掌号“新增内容接口”提交的数据,在质量校验合格后可以在24小时内抓取并展现,但每天会有固定的提交配额限制;(对中小企业来说,提交配额完全足够了)
在Spider抓取这个环节,影响线上展现的因素有:
1、网站封禁。你别笑,真的有同学一边封禁着百度蜘蛛,一边向百度狂交数据,结果当然是无法收录。
2、质量筛选。百度Spider进入3.0后,对低质内容的识别上了一个新台阶,尤其是时效性内容,从抓取这个环节就开始进行质量评估筛选,过滤掉大量过度优化等页面,绝大多数网页抓取后不展示的原因就是页面不够优质。
3、抓取失败。抓取失败的原因很多,有时你在办公室访问完全没有问题,百度spider却遇到麻烦,站点要随时注意在不同时间地点保证网站的稳定性。
4、配额限制。虽然我们正在逐步放开主动推送的抓取配额,但如果站点页面数量突然爆发式增长,还是会影响到优质链接的抓取收录,所以站点在保证访问稳定外,也要关注网站安全,防止被黑注入。
搜索引擎的检索概述
前面简要介绍过了搜索引擎的索引系统,实际上在建立倒排索引的最后还需要有一个入库写库的过程,而为了提高效率这个过程还需要将全部term以及偏移量保存在文件头部,并且对数据进行压缩,这涉及到的过于技术化在此就不多提了。今天简要给大家介绍一下索引之后的检索系统。
检索系统主要包含了五个部分,如下图所示:
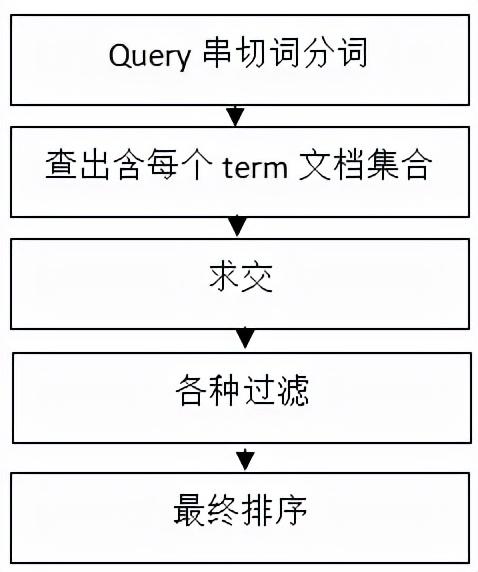
1、Query串切词分词即将用户的查询词进行分词,对之后的查询做准备。
2、查出含每个term的文档集合,即找出待选集合
3、求交,上述求交,文档2和文档9可能是我们需要找的,整个求交过程实际上关系着整个系统的性能,这里面包含了使用缓存等等手段进行性能优化;
4、各种过滤,举例可能包含过滤掉死链、重复数据、色情、垃圾结果以及你懂的;
5、最终排序,将最能满足用户需求的结果排序在最前,可能包括的有用信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配程度、分散度、时效性等等,之后会详细给大家介绍。
熊掌号
之前百度是没有熊掌号这个产品的,现在有了熊掌号,简直是网站收录神器,我们来看看官方的介绍: